Qwen 模型小记(二)
相关信息
针对 2024-2026 年初 Qwen 模型作简要摘录,具体性能待测试后完善。
Qwen 3
- 博客:Qwen3:思深,行速
- huggingface:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
- arxiv:https://arxiv.org/pdf/2505.09388
大约在 25 年 4 月份推出的开源模型,对标 deepseek R1 和 o1,包括 Qwen3-235B-A22B 、 Qwen3-30B-A3B 、 Qwen3-32B 、 Qwen3-14B 、 Qwen3-8B 、 Qwen3-4B 、 Qwen3-1.7B 和 Qwen3-0.6B 。模型支持了
- 思考模式和非思考模式
- 多语言支持
- 增强的 Agent 能力
| Models | Layers | Heads (Q / KV) | Tie Embedding | Context Length |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-1.7B | 28 | 16 / 8 | Yes | 32K |
| Qwen3-4B | 36 | 32 / 8 | Yes | 32K |
| Qwen3-8B | 36 | 32 / 8 | No | 128K |
| Qwen3-14B | 40 | 40 / 8 | No | 128K |
| Qwen3-32B | 64 | 64 / 8 | No | 128K |
MOE 模型参数:
| Models | Layers | Heads (Q / KV) | # Experts (Total / Activated) | Context Length |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 128K |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 128K |
根据官网的指标来看,235B-A22B 的模型,似乎能和 OpenAI-o1 比一比。
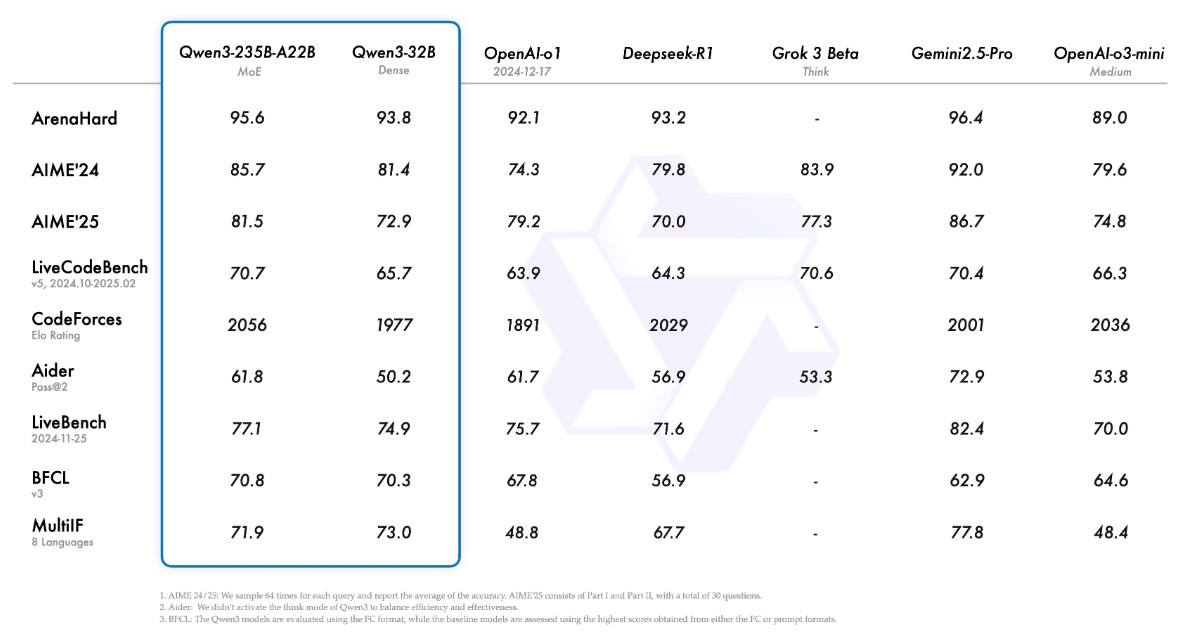
而 30B-A3B 的模型,似乎能和 GPT-4o 比一比?
- 架构
Dense 模型,相比于 Qwen2.5,Qwen3 同样使用 GQA, SwiGLU, RoPE,pre-norm 的 RMSNorm, 同时移除 QKV-bias,使用 QK-Norm 。
MOE 版本同样采用了 fine-grained expert segmentation,Qwen3-MOE 中有 128 个 expert,8 个 activated experts,不采用 shared experts。采用了 global-batch load balancing loss 来促进模型的专业性。
- 预训练
总共采用了 119 种语言,36T 的 token
- General stage:先在 30T 上进行 4096 长度的预训练
- Reasoning Stage:增加 STEM, coding, reasoning 和一些合成数据,模型在大约 5T 这样的高质量 token 下进行训练,该阶段加速学习率递减。
- Long Context Stage:再不到 1T 的 token 上,进行 32K 预训练,预训练数据包括了 75% 16k-32k 的数据,25% 4k-16k 的数据,RoPE base 改成 1000000。采用 YARN + Dual Chunk Attention。
- 后训练
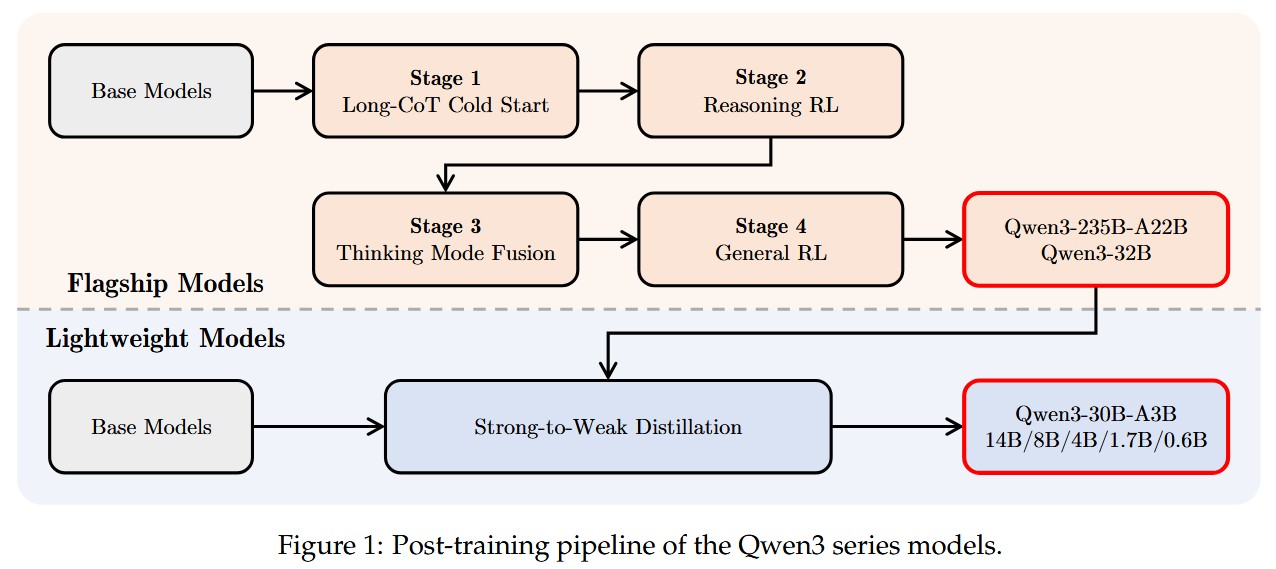
- Long-CoT Cold Start:使用长思维链的 STEM 数据训练。用 Qwen2.5-72B-Instruct 审核 query 数据,包括 Qwen2.5-72B-Instruct 不需要使用 CoT 就能回答正确的 query,控制相关 query 的 domain 分布等。有 query 后,使用 QwQ-32B 生成 N 个候选回复,然后由人工标注员标注筛选,剔除以下类型的回答:
- 产生错误最终答案的回答;
- 包含大量重复内容的回答;
- 明显表现为猜测、但缺乏充分推理过程的回答;
- 推理过程(thinking)与总结内容(summary)之间存在明显不一致的回答;
- 存在不恰当语言混用或风格突变的回答;
- 被怀疑与潜在验证集样本过于相似的回答。
- Reasoning RL:约 4000 对 query-verifier 训练对,数据集难度需要有很好的控制,而后利用基于规则的奖励 + GRPO 调参。
- Thinking Mode Fusion:通过 chat template 和额外的 SFT 来使模型可以再 think 和 non-think 两种模式之间切换。
- General RL:采用了 rule-based reward, model-based reward wIth/without reference answer 三种不同的奖励,评分模型使用 Qwen2.5-72B-Instruct。
Qwen3-Coder
25 年 7 月左右发布的模型,主要对标 Cluade Sonnet4。同时官方还推出了 Qwen Code,通过 prompt 和工具调用协议适配来最大发挥 Qwen3-Coder 的效果。
模型分为 480B-A35B,30B-A3B 2 个规模,这两个规模都有对应的 FP8 版本
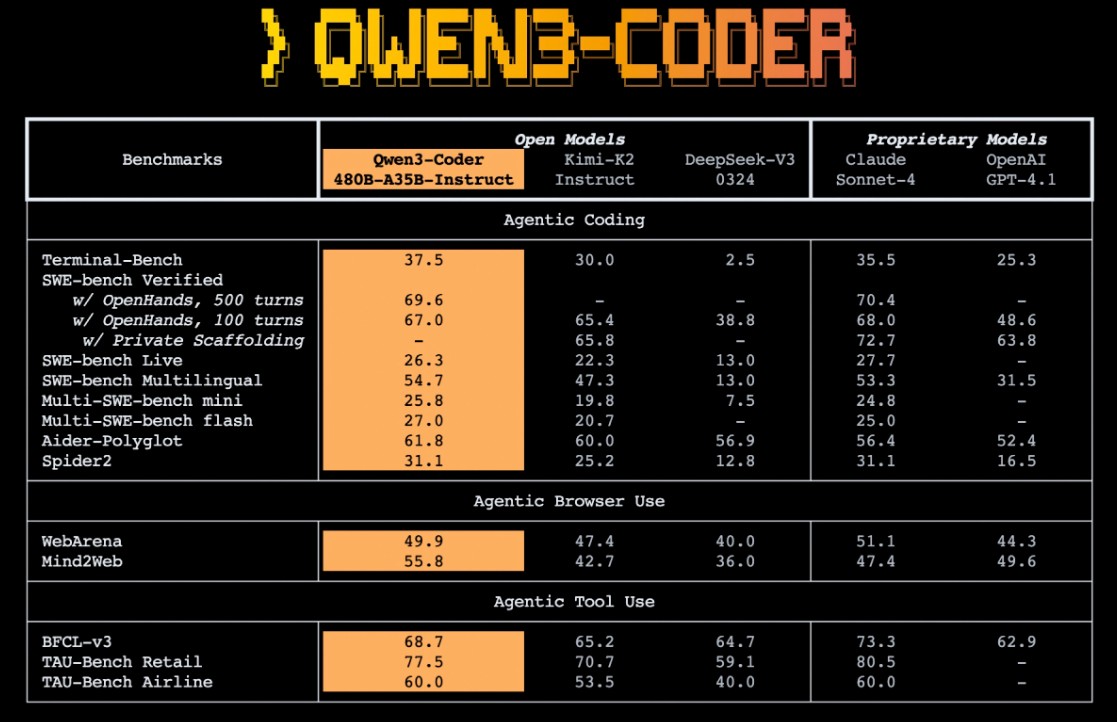
- pre-training:共 7.5T 数据,代码站 70%。原生支持 256K 上下文,借助 YaRN 可拓展至 1M;利用 Qwen2.5-Coder 对低质数据进行清洗与重写。l
- post-training:看介绍,似乎使用了 rule-based reward 进行 RL 外,还对 Long-Horizon RL 类型任务进行了专门的 RL。
Qwen-Image
25 年 8 月多开源的模型,主打文本渲染和图像一致性。
主要结构如下:
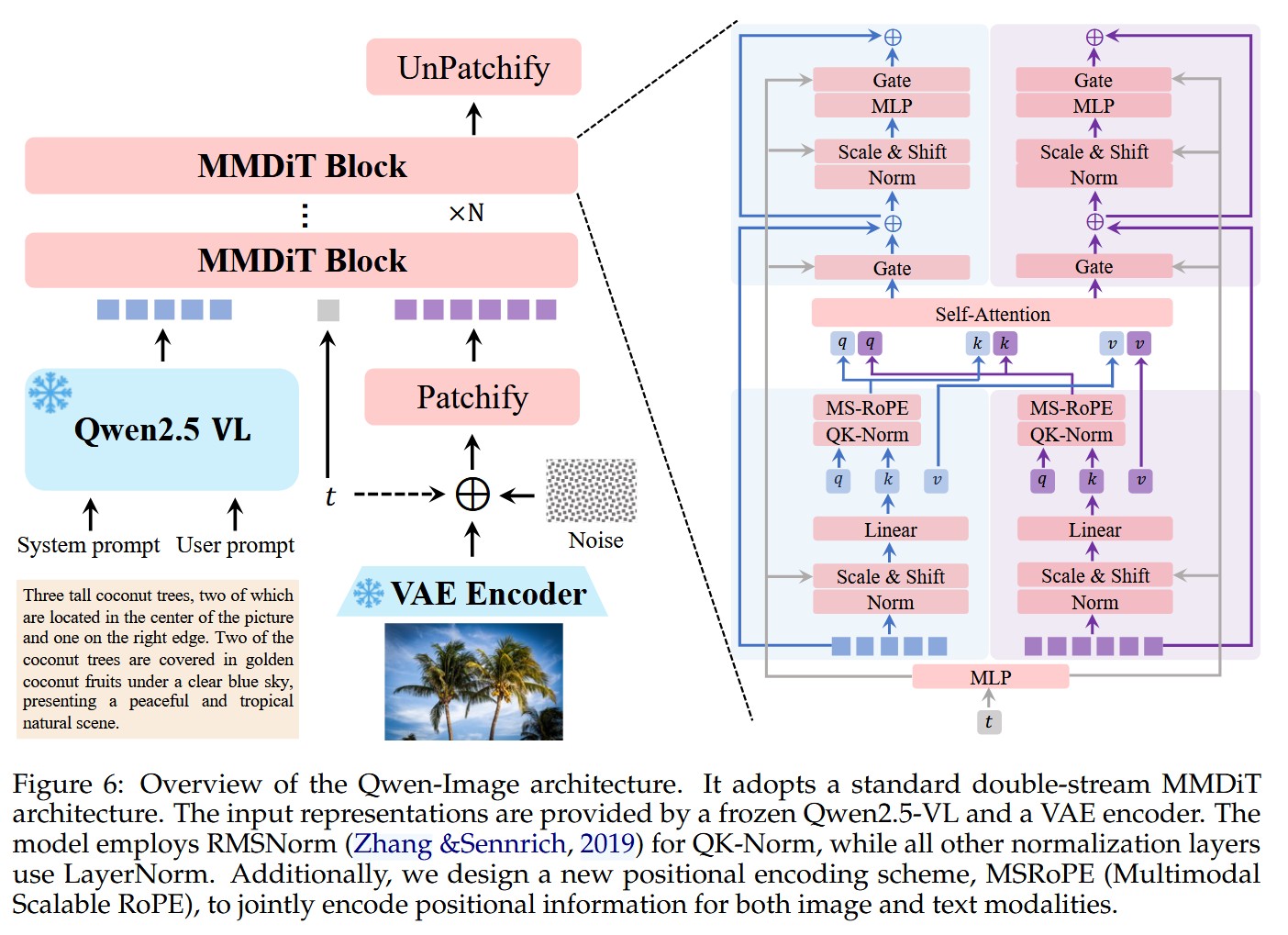
其中的 MMDIT 架构也进行了优化,包括采用不同的文本编码器,和 MSRoPE。
整个数据过滤分成了 7 个不同的 stage,如下图。其中的 p 表示 pixel,灰色表示被抛弃的数据。Image-Text 对齐训练时,同时采用了原始文本,Qwen-VL 生成的文本进行对齐训练。
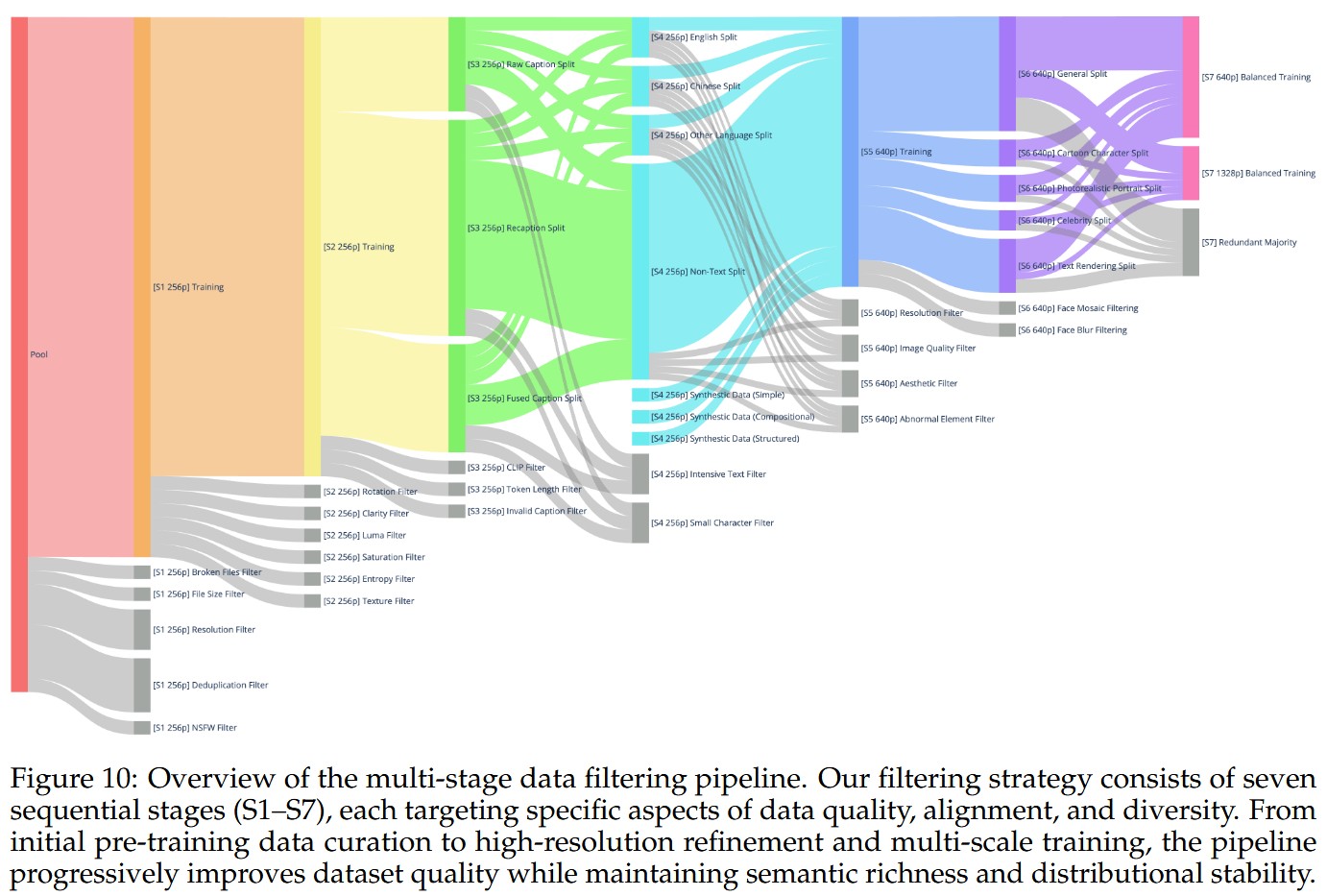
- 预训练
- 分辨率提升 :256 → 640 → 1328,逐步学习从整体结构到细节特征。
- 文本能力引入 :先训练无文本图像,再加入带文字图片,提升文字生成能力。
- 数据质量提升 :前期用大规模数据,后期通过严格筛选使用高质量数据。
- 数据分布平衡 :逐步平衡不同领域和分辨率的数据,避免过拟合。
- 合成数据增强 :用 synthetic data 补充稀缺场景(如超现实风格或大量文字图像)。
- SFT:提高了数据质量,人工标注数据
- RL:先 DPO 大规模 RL,而后 GRPO 精进。
Qwen-Image-Edit
基于 20B 的 Qwen-Image 进行进一步训练,使得模型的图像编辑能力得到了进一步提升。官方给的示例来看,一致性还是很不错的。
huggingface 的评论好像挺多说效果不如 demo,实际测试下来,使用原版 FP16 进行推理,即便使用 4 step LORA,在提示词合格情况下出图效果不错;但使用 FP8 推理时,生图效果堪忧。用 A100 80GB 推理,原生 huggingface + FP16 + 4 step lora 一张图片出图不到 4 秒钟。
模型支持多图输入与文字 Prompt 组合,例如让图 1 中的人物穿上图 2 的服装,并手持图 3 的扇子。在这类场景下,需要更精细地设计和调整 Prompt,才能获得更符合预期的生成效果。
主打一个开源:https://huggingface.co/Qwen/Qwen-Image-Edit-2511
参考 2511 的版本,encoder 用的是 7B 的 Qwen2.5-VL,huggingface 上开源版本实际参数估计有个 8B 左右。解码器部分用的 QwenImageTransformer2DModel 大概 20B 参数。
Qwen3-Next
开源了 Qwen3-Next-80B-A3B 的 instruct 和 thinking 两种不同的模型。相对于之前 Qwen3-A3B 的 MoE 有很大提升,但还是比 A22B 版本差一点。跑 256K 需要 4 个 GPU。
相对于 qwen3,该版本进行了一下改进:
- 混合注意力架构: Gated DeltaNet + Gated Attention
团队发现 Gated DeltaN 相对于滑动窗口注意力 和 Mamba2 有更强的 in-context learning 能力。在 75%层使用 Gated DeltaNet, 25% 用标准注意力情况下能实现性能与效率的双重优化。
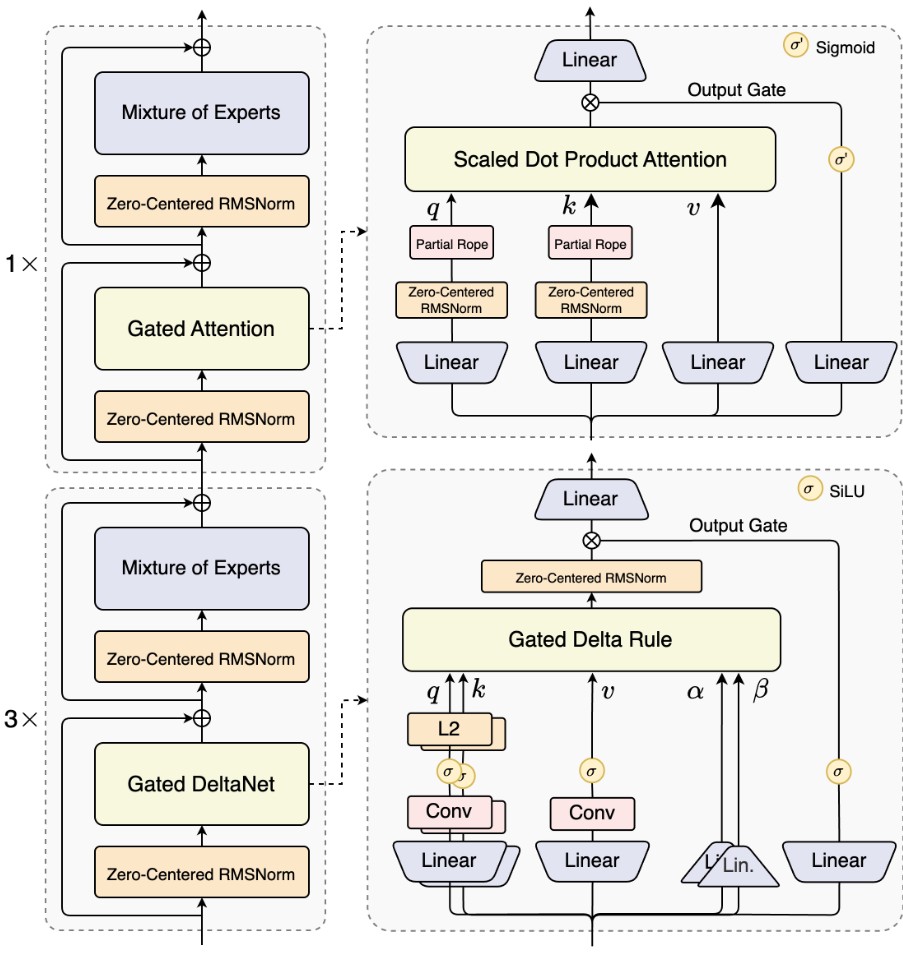
- 稀疏 MoE: 仅激活 3.7% 参数。
团队实验发现,在全局负载均衡后,当激活专家固定时,持续增加专家总参数可带来训练 loss 的稳定下降。
- MTP:引入了 DeepSeek-V3 中的 MTP。
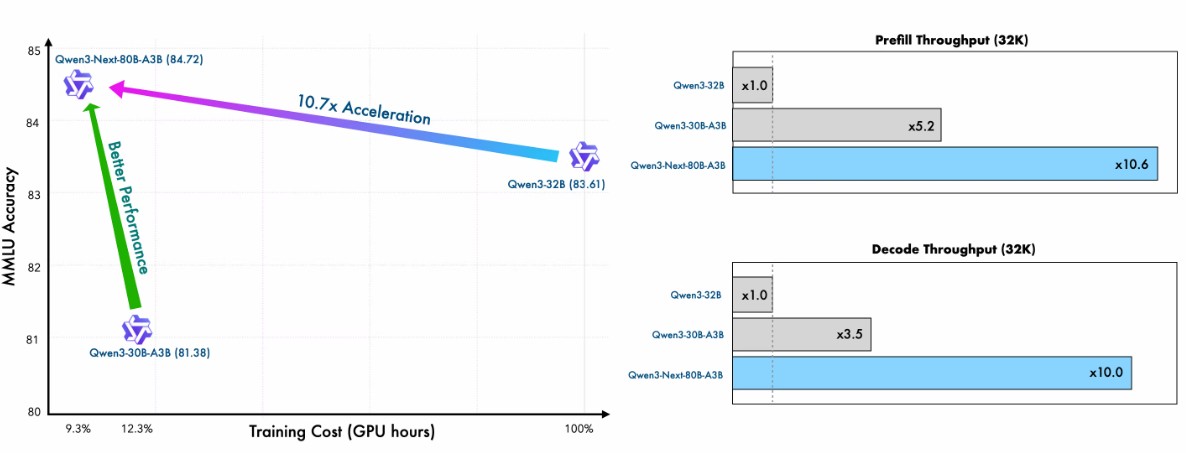
可以看出在训练效率和推理速度来看,Next 版本都有很大的优化。效果也不会很差,:
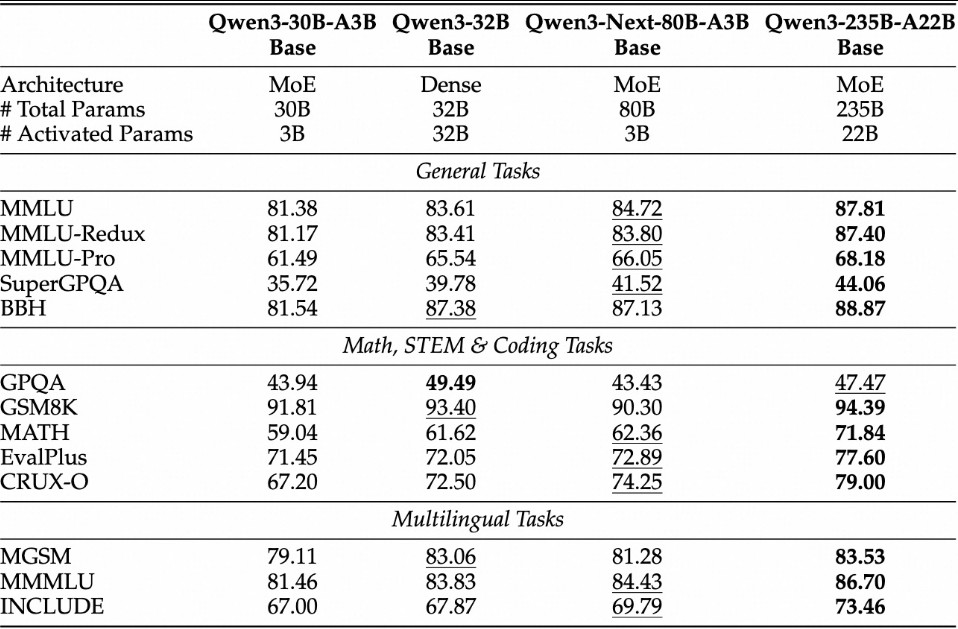
Qwen3-TTS
主打开源,开源模型如下:
| 模型 | 特性 | 语言支持 | 流式支持 | 指令控制 |
|---|---|---|---|---|
| Qwen3-TTS-12Hz-1.7B-VoiceDesign | 根据用户提供的描述进行音色设计。 | 中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文、意大利文 | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-CustomVoice | 通过用户指令对目标音色进行风格控制;支持 9 种优质音色,涵盖不同性别、年龄、语言和方言的组合。 | 中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文、意大利文 | ✅ | ✅ |
| Qwen3-TTS-12Hz-1.7B-Base | 基础模型,支持从用户提供的 3 秒音频快速克隆音色;可用于微调(FT)其他模型。 | 中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文、意大利文 | ✅ | |
| Qwen3-TTS-12Hz-0.6B-CustomVoice | 支持 9 种优质音色,涵盖不同性别、年龄、语言和方言的组合。 | 中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文、意大利文 | ✅ | |
| Qwen3-TTS-12Hz-0.6B-Base | 基础模型,支持从用户提供的 3 秒音频快速克隆音色;可用于微调(FT)其他模型。 | 中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文、意大利文 | ✅ |
以下是官方给的一个实例:
import torch
import soundfile as sf
from qwen_tts import Qwen3TTSModel
model = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-CustomVoice",
device_map="cuda:0",
dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
# single inference
wavs, sr = model.generate_custom_voice(
text="其实我真的有发现,我是一个特别善于观察别人情绪的人。",
language="Chinese", # Pass `Auto` (or omit) for auto language adaptive; if the target language is known, set it explicitly.
speaker="Vivian",
instruct="用特别愤怒的语气说", # Omit if not needed.
)
sf.write("output_custom_voice.wav", wavs[0], sr)
Qwen3-Omni
25 年 9 月发布的模型,对标 GPT-4o 和 Gemini 2.5 系列,其中 30B-A3B 的模型开源了。官方宣传端到端音频对话延迟 211ms,视频对话延迟 507ms。
25 年 12 月更新了 Qwen3-Omni-Flash,官方指标比 Qwen3-Omni 30B-A3B 好点,但似乎没开源。

Qwen3-Omni 相对 2.5 版本增加了输入音频的长度(提高到 40 分钟),减少了 streaming 延迟,主要更新:
- 同样采用 qwen2.5 o-mini 的 thinker-talker 架构,但 thinker,talker 都更新成了 MoE。
- 将 Whisper audio encoder 替换成了 Audio Transformer encoder(在 20 Million 小时音频监督数据上从零开始训练的模型)
- speech 生成部分,采样用了 multi-codebook representation,论文表示可以提高输出的非语义信息,如音色等。
- talker 改成了 multi-track codec modeling(通过 MTP 预测多个 codebook layers);Code2Wav 部分将 DiT 换成了轻量的 ConvNet。
- 输入和输出的 audio code rate 减少到了 12.5Hz,输出编码器支持 single-frame, immediate speech synthesis。
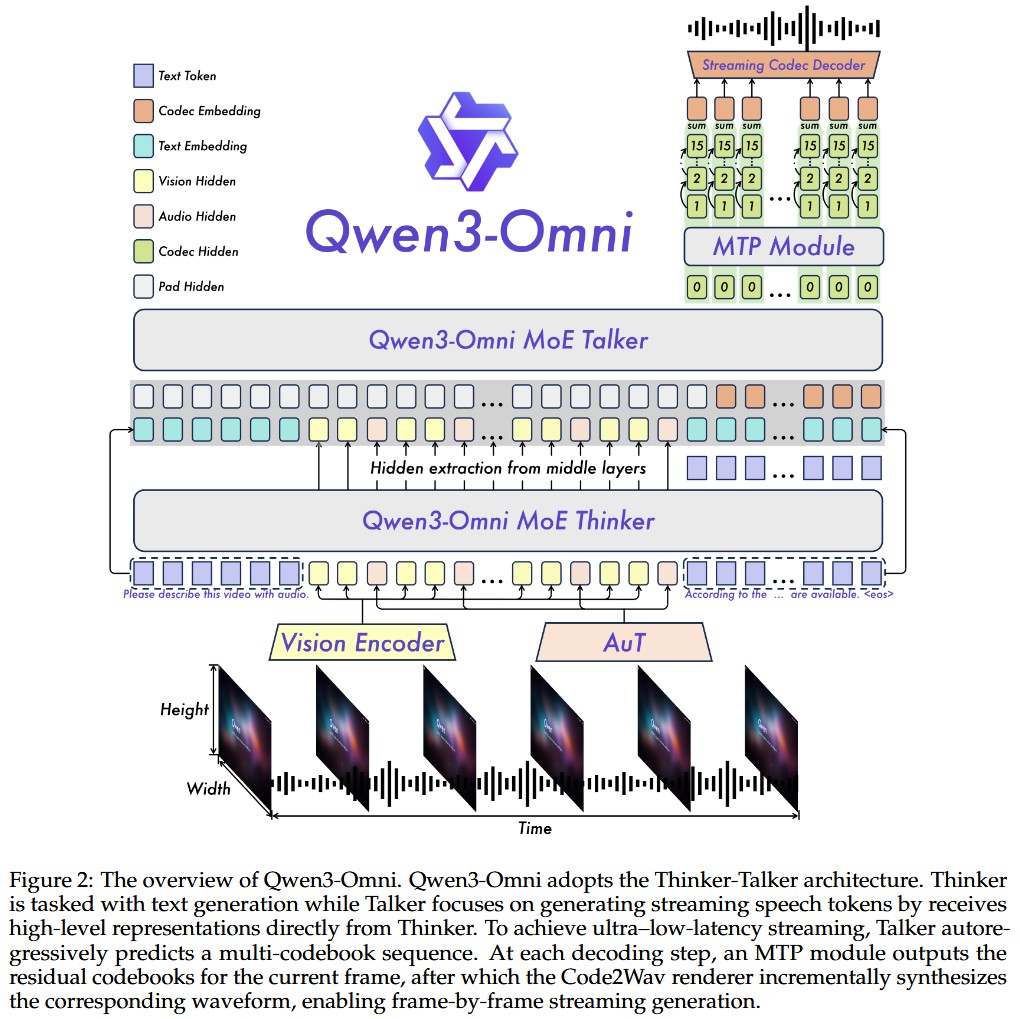
模型各个阶段参数:
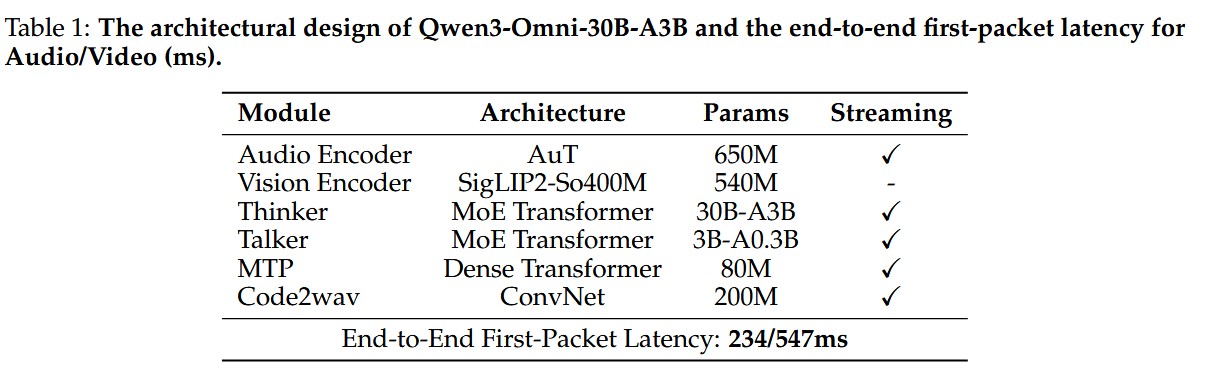
其中 AuT 架构如下:
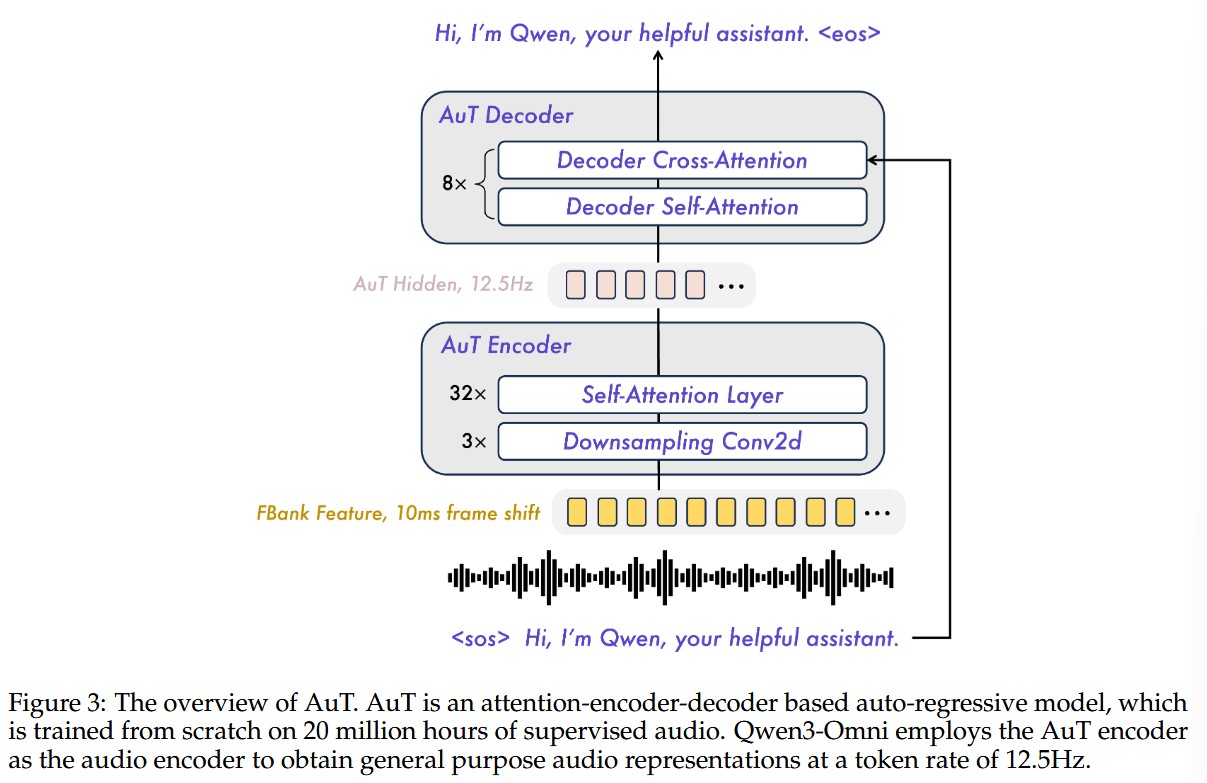
- 预训练
- 阶段一:LLM 用 Qwen3,Vision Encodder 用 Qwen3-VL,audio encoder 用 AuT。锁定 LLM, 训练其他 2 个部分。
- 阶段二:在总计 2 T tokens 数据集上训练(窗口 8192),文本 0.57 T, 音频 0.77 T, 图片 0.82 T,视频 0.05 T。
- 阶段三:窗口改为 32 k。提升长文本和长音频数据占比。
Qwen3Guard
Qwen3Guard-Stream 专为低延迟设计,可在模型逐词生成回复的过程中实时进行内容审核。
huggingface 中开源了 2 中不同架构的模型,其中 Qwen3Guard 架构与 Qwen3forCasualLM 相同。针对整个语句生成固定格式的回复,如:
# '''
# Safety: Safe
# Categories: None
# Refusal: Yes
# '''
而 Stream 版本架构采用了 Qwen3ForGuardModel 架构上大致与 Qwen3 预训练模型差不多,在输出上加了个分类层,添加了 stream 处理相关函数。所以可以再 stream 的时候对每个 token 进行分类预测。
Qwen-Image-Layered
模型主要目的是将图片分解成可编辑的 RGBA 图层,有开源,不知道效果怎么样。

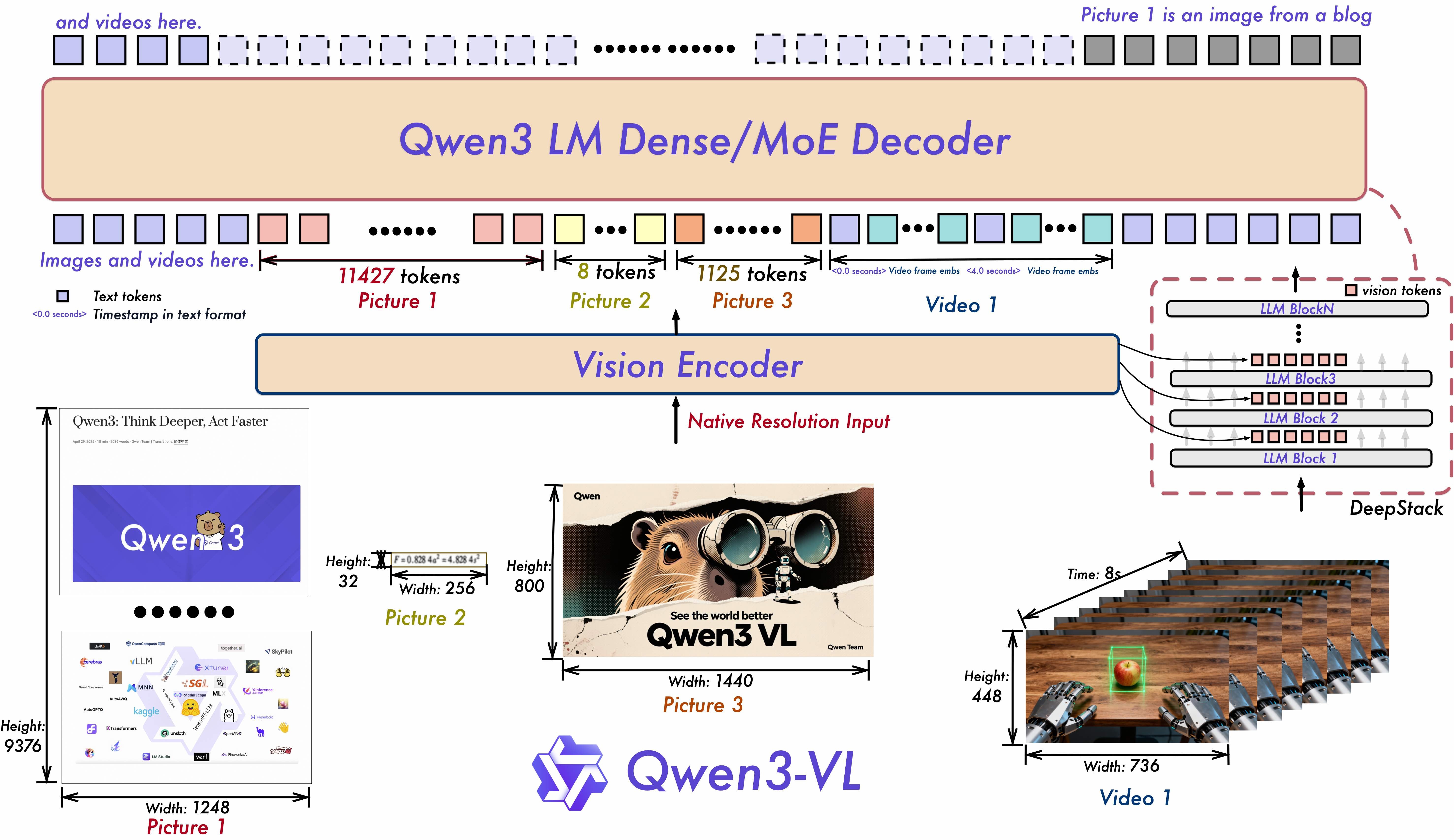
Qwen3-VL
开源了 2B,4B,8B,32B,30B-A3B, 和 235B-A22B 。其中 A22B 模型的视觉能力对标 Gemini-2.5pro,和 GPT5,Claude-Opus-4.1。
从 Demo 视频的时间来看,图像 Agent 的延迟还是有点高。
架构相对于 Qwen2.5 VL 做了更新。
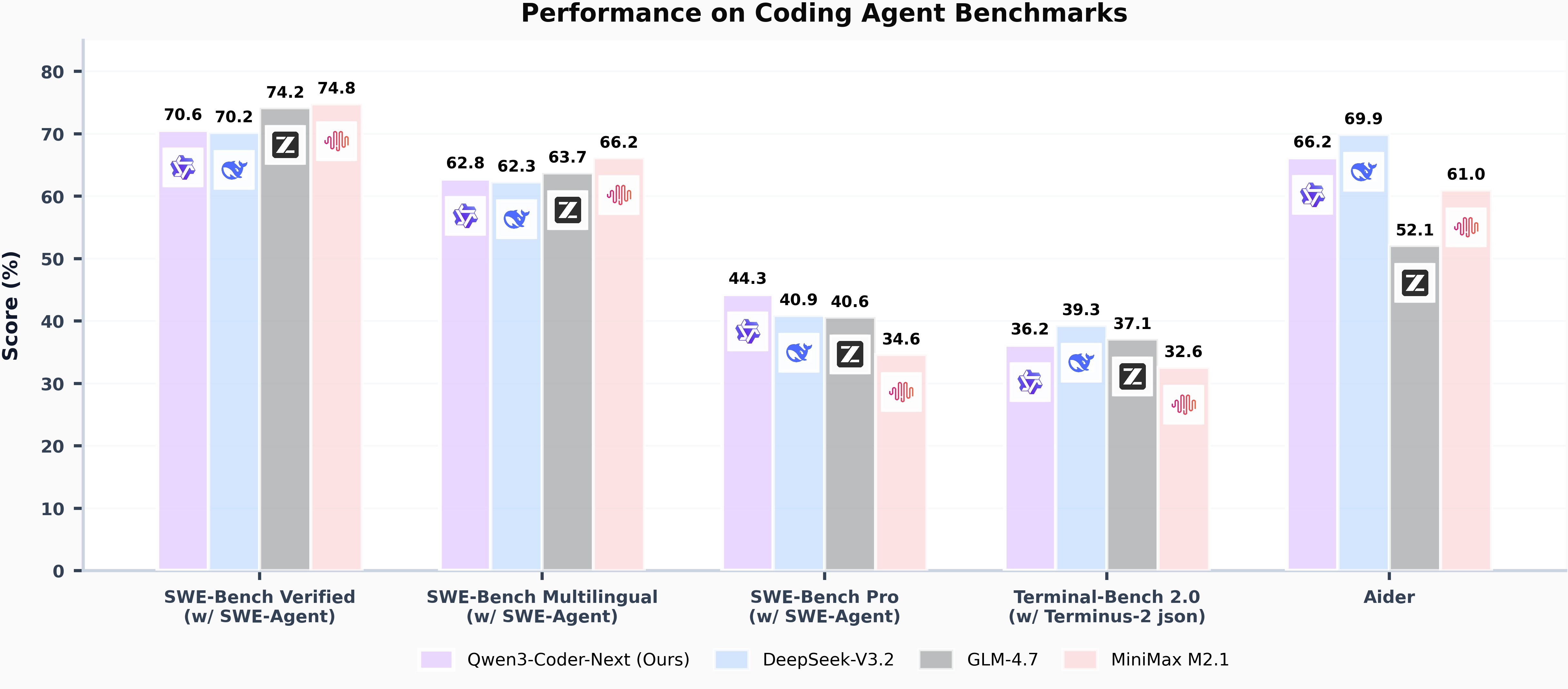
Qwen3-Coder-Next
开源,基于 Qwen3-Next-80B-A3B-Base 构建,目标本地开发。
Qwen3.5
对标 GPT-5.2, Claude Opus 4.5,Gemini 3 Pro。
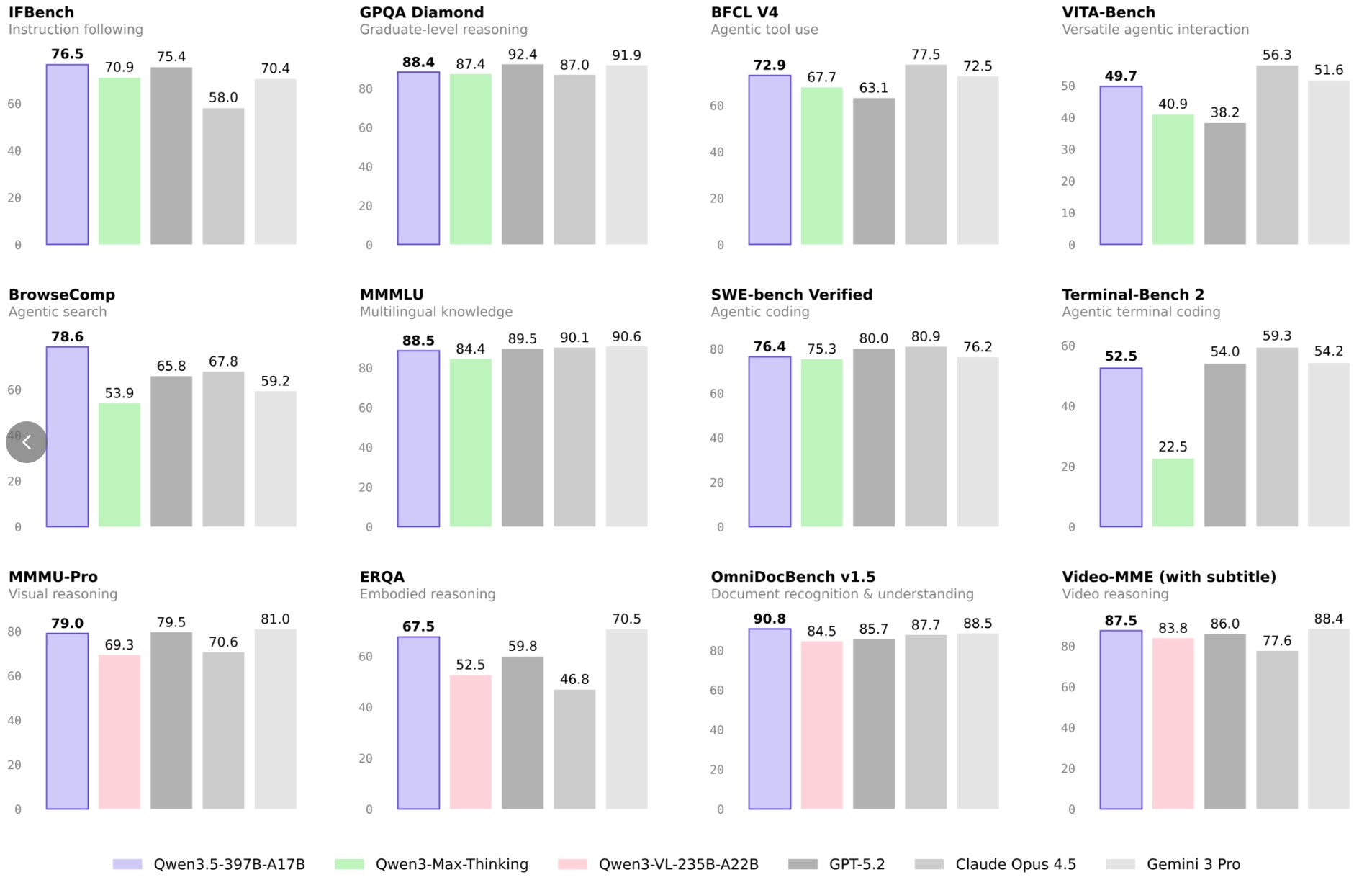
- 架构: 与 Qwen3-Next 相同。
- 预训练:博客中提到在更大规模的视觉-文本语料上训练
- 后训练:博客中提到 Qwen3.5 的 Post-training 性能提升主要来自于我们对各类 RL 任务和环境的全面扩展。