熵、MDL 和压缩
对熵,编码长度,MDL,压缩,柯氏压缩器的回忆梳理。
一、熵与编码长度
本节观点
熵就是一个随机变量能够被压缩到的“平均最短编码长度”的理论极限。
如果模型的平均编码长度越短,那么他和数据的真实分布(真实熵)就越接近。因为根据 cross-entropy(交叉熵) ,它和真实熵关系是:
1.1 熵
看一个单个事件 ,它的信息量定义为:
含义是越罕见的事,信息量越大;越常见的事,信息量越小。因为如果一个事件概率很小,你看到它时会更“惊讶”。熵就是对这种“信息量”的平均:
也就是: 按真实分布抽样时,平均每个样本给你带来多少 surprisal。
1.2 Shannon 源编码定理
信息论里最经典的结论之一。对于一个离散无记忆信源,平均码长 不可能低于熵:
而且存在编码方法,使平均码长可以无限逼近熵。
1.3 最优编码长度
对于一个概率为 的事件,最优编码长度应该是
下部分为证明平均长度:
代入:
得到
所以: 熵 = 最优平均编码长度
证明 step 1: Kraft inequality
对于一个 二进制前缀编码 ,如果编码长度为
那么必须满足
直觉:想象一棵 二叉树表示所有编码 :
(root)
/ \
0 1
如果某个符号编码长度是 ,它就在树的 第 层 。例如:
| 符号 | 编码 | 长度 |
|---|---|---|
| A | 0 | 1 |
| B | 10 | 2 |
| C | 11 | 2 |
树结构:
*
/ \
A *
/ \
B C
每个节点占据树的一部分空间。而第 层总共有
个可能位置。所以一个长度为 的编码占据
的树空间,因此所有编码占据空间:
如例子中的 必须 ≤ 1,否则树放不下。
证明 step 2: 最优码长
最优解一定会把 Kraft 约束“用满”一定满足
相当于一个二叉树下每个节点都分配了一个 token;如果合法码长 我们可以定义:
于是 就是一个概率分布,所以平均码长变成
也就是
因此最小值在 时取得,也就是
二、MDL
本节观点:
“面对数据时,什么样的模型最好?”
最好的模型,是让“模型本身的描述长度 + 用这个模型描述数据剩余部分的长度”之和最短的模型。
2.1 MDL ,熵,最短编码
Minimum Description Length,MDL 的思想是:
针对上面这个评判标准,最小的模型最好。意思是:
- 模型本身也要花 bit 表示。这与模型本身大小没有关系,与能 跑起来 这个模型需要花费的 bit 有关系,有些模型只需要几 KB 的代码就能启动了。
- 数据在给定模型后,剩余还需要多少 bit,也对应最短编码长度。从直觉上来说,如果模型预测得很好,那么剩余误差就少,需要补充的额外信息就更短。如果模型预测得不好,那么你得补大量“纠正信息”,编码就长;从熵角度理解,任何数据都有随机性,但他的最优是固定的:。模型约接近这个编码长度,预测越好。
- 两者加起来越短越好。
MDL 提出一个好模型,不只是拟合数据,还要让“模型本身 + 数据剩余”的总编码长度最短。
相关信息
似乎大家默认,越简短的道理,越具有”智慧“,越有泛化性。
2.2 MDL 对应到 AR 的 LLM
其中:
- 是数据序列
- 是模型 给出的概率分布
- 是模型本身的编码长度
- 就是 LLM 的 next-token training loss
三、压缩
LLM + 算数编码可以实现无算压缩
3.1 算数编码的长度
算术编码不是给每个符号单独分配一个固定码字,而是:
- 把整个消息映射到 区间里的一个很小的子区间
- 子区间越小,表示这条消息越罕见
- 最后只需要输出一个能唯一落在这个区间内的二进制数
假设一开始整个区间是:
长度是 1。
如果第一个符号 的概率是 ,那选完后新区间长度变成:
如果第二个符号在前文条件下的概率是 ,那新区间再缩小这么多倍,长度变成:
继续下去,到第 个 token 后,最终区间长度是:
而根据链式法则:
所以:
例子
一个简单例子,假设字母表只有三个符号:
- A: 0.5
- B: 0.3
- C: 0.2
初始区间:
按概率切分成:
- A:
- B:
- C:
如果消息第一个字符是 B,那么区间缩小成:
如果第二个字符还是按同样分布,且是 A,那么再把 按 0.5/0.3/0.2 切分,A 对应前 50%,新区间长度就变成:
如果第三个字符是 C,那么最终区间长度变成:
注意这个长度恰好就是整条序列概率:
如果一个区间长度是 ,要用二进制小数唯一指定这个区间里的一个点,大约需要:
bits,而算术编码里,对整条序列 :
所以总码长约为:
如果把序列概率按链式法则展开:
那么总码长就是:
这已经非常接近 LLM 的训练目标了。
3.2 LLM 预训练与算数编码
LLM 与算术编码结合的压缩器,整个系统由两部分组成:
A. 概率模型:LLM
它在每一步根据前文输出:
也就是“下一个 token 是词表里每个 token 的概率”。
B. 熵编码器:算术编码
它拿到这组概率后,把真实出现的那个 token 编成一个尽可能短的 bit 表示。
步骤 0:准备
压缩端和解压端必须事先共享:
- 同一个 tokenizer
- 同一个 LLM 初始化权重
- 同一种算术编码规则
- 同样的起始上下文规则,比如 BOS token
- tokenize 后的 tokens
否则解码端没法复现同样的概率分布。
步骤 1:LLM
对于第 步:
- 已知前文
- LLM 前向传播,输出一个词表上的分布:
- 选中你想发送的 token 作为 ,然后进行反向传播更新参数 。
步骤 2: 算数编码
对于第 t 布,算术编码器就会:
- 按这组概率把当前区间切分
- 选中真实 token 所对应的那个子区间
- 把区间缩小到那里
步骤 3:最终输出
在 LLM 前向传播完最后一个 token 后,算数编码会同步得到一个区间,输出一个能唯一落在该区间中的二进制小数,就可以唯一代表整段文本。
LLM 和压缩
LLM 预训练时候,loss 曲线下面的面积(横轴 num token,纵轴 loss),就是平均编码长度。注意训练 loss 可能是以自然对数为底,需要进行单位换算成 bit,然后再换算成 bytes。
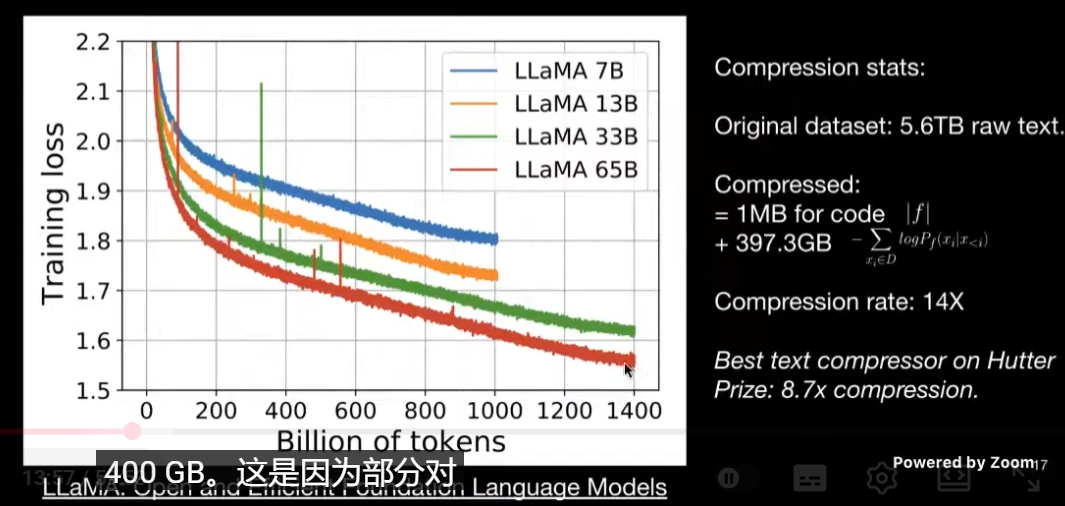
四、柯氏复杂度
4.1 无监督训练的直觉
考虑某个算法 A,他尝试对未知的 Y 进行压缩,但目前我们能使用的数据只有 X。
因为如果数据里真有规律,那么:
- 有规律的数据可以被更短地描述
- 没规律的数据就只能原样存下来
我们尝试对 X 进行压缩,希望能够充分提取出 X 中能对预测 Y 有帮助的规律。
4.2 Kolmogorov complexity 的定义
固定一个通用图灵机 。定义:
也就是说, 是所有能让通用机 输出 的程序里,最短那个程序的长度。
因此 Kolmogorov compressor 本质上是搜索所有的程序,然后给出最好的那个。
如果你已经有了一个可计算压缩器 ,那要生成 ,你只需要:
- 一个实现压缩器/解压器 的程序
- 再加上压缩后的比特串
于是,“生成 的一个程序”的总长度,最多就是:
而 是“生成 的最短程序长度”,既然我们已经构造出一个能生成 的程序,它的长度不超过上面这个量,所以:
本质就是一句话 任何可计算压缩器给出的压缩结果,都不能比 Kolmogorov complexity 好太多;因为 K 机可以模拟它。
4.3 程序与逻辑
NN/Transformers 不仅仅是函数模拟器,可以把它看成一台资源有限的计算器:
- 有一定 memory
- 有一定 sequential steps(层数、推理步数)
- 有大量并行操作
当代计算器通过 各类逻辑门 来实现所有操作,包括运算转换查找等等,NN 网络能实现逻辑门,因此理论上能实现当代计算机的各种操作。
4.4 NN 相当于 迷你 Kolmogorov compressor
使用 SGD 进行训练时候,各个参数的调整,有点像是在重新摆放和安排成千上万个逻辑门。SGD 优化可以看做根据这些数据,寻找一个最好的压缩器。
4.5 AR 系列 LLM 的预训练直觉
根据前面的直觉,压缩 = 学到结构,那么
其中 Y 是我们要预测的东西,而 X 是我们已经有的数据集,不是单个样本。
因此如果我们用这个 Kolmogorov complexity 来压缩 Y(在能够查找和访问数据集 X 的情况下),一定会比其他程序好。压缩好也意味着预测好。
现实里,直接“条件在一个巨大的数据集 上”这件事,其实不太自然,也不太可操作。(我们可以用一个模型在数据上训练,去 fit a big dataset,但是很难去随时访问这个超大的数据集 X,也就是 condition on it,这个工程上实现难度大)
如果你要对 Y 进行预测, 可以不用 conditional compressor ,只用普通的 Kolmogorov compressor 去压缩 的拼接 ,效果本质上也一样好。
这其实是 Kolmogorov complexity 里的一个经典链式规则,意思是:
联合描述 和 的复杂度,约等于:
- 先描述
- 再在 已知的条件下描述
也就是说:
- :同时生成 这对对象所需的最短程序长度
- :单独生成 的最短程序长度
- :在允许访问(查找) 的条件下生成 的最短程序长度
而右边那个小误差项:
表示这里不是严格相等,而是差一个比较小的 bookkeeping 开销
所以我们再上面提到一个 LLM 进行预训练,其实就是在这个预训练数据集上做压缩,这个模型可以说理论上能够逼近我们想要的这种 Kolmogorov compressor。
4.6 linear representations
在 2020 年左右,openai 提出的 iGPT 通过 next pixel prediction 对图像领域任务的压缩和预测,模型效果在当时不错,同期他们也对不同 scale 的模型和任务进行了测试,提出对应的 scaling laws。
尽管压缩理论没有直接解释模型得出的表征为什么是线性分布的,但似乎 AR 模型的表征会比 BERT 系列的好。